Du möchtest wissen, was ein Data Lake genau ist und welche Chancen er für Unternehmen bereithält? Hier und im Video erfährst du es!
Inhaltsübersicht
Was ist ein Data Lake?
Ein Data Lake (deutsch: „Datensee“) beschreibt in der Informatik einen sehr großen Speicher, in dem Daten in ihrem Rohformat gespeichert werden. Das bedeutet, dass ein Data Lake auch unstrukturierte Daten wie Bilder oder Videos aus den verschiedensten Quellen problemlos aufnehmen kann.

Damit kann ein Data Lake einem Unternehmen einen großen Wettbewerbsvorteil verschaffen.
Beispiel: Ein Unternehmen könnte in einem Data Lake all seine Verkaufstransaktionen analysieren. Dabei können Logdateien, Kundenmeinungen oder Daten aus Clickstreams und sozialen Medien mit einbezogen werden. So wird es leichter, personalisierte Werbung zu schalten oder Preise festzulegen.
Data Lake vs. Data Warehouse
In Bezug auf die Speicherung großer Datenmengen („Big Data“ ) fällt oft nicht nur der Begriff Data Lake, sondern auch Data Warehouse.
Das liegt daran, dass Data Lakes und Data Warehouses ähnlich genutzt werden:
- Sie sind beide Speicherrepositories für große Datenmengen.
- Sie fungieren beide als zentralisierter Speicher, der Daten an unterschiedliche Anwendungen weitergibt.
Allerdings unterscheiden sie sich fundamental in ihren Konzepten und der Art der Datenspeicherung:
-
Data Lakes:
Ein Data Lake nimmt Daten aus unterschiedlichen Quellen in ihrem Rohformat auf und legt sie unstrukturiert ab. Der Data Lake muss außerdem nicht den Analysezweck der Daten kennen. Denn erst, wenn die Daten tatsächlich benötigt werden, erfolgt die Suche, Strukturierung und Umformatierung.
-
Data Warehouses:
Ein Data Warehouse speichert dagegen in der Regel strukturierte Daten wie Kennzahlen oder Transaktionsdaten ab. Hier ist der Analysezweck auch schon im Vorhinein bekannt. Das Data Warehouse führt die Daten aus unterschiedlichen Quellen zusammen und überführt sie vor der Ablage in passende Formate und Strukturen. Nicht benötigte Informationen löscht es direkt. Damit erlaubt ein Data Warehouse eine direkte Analyse.

Hier findest du nochmal alle wichtigen Unterschiede auf einen Blick:
| Data Lake | Data Warehouse | |
| Datenstruktur | roh | verarbeitet |
| Zweck der Daten | noch nicht festgelegt | bekannt |
| Datenaufbereitung | erst, wenn die Daten benötigt werden | vor der Ablage |
| Benutzer | Data Scientists | Business-Anwender |
| Zugänglichkeit für Benutzer | komplex, Nutzer muss sich mit den unterschiedlichen Datenarten und ihren Beziehungen auskennen | einfach, da strukturiertes Schema |
| Flexibilität | passt sich leicht an Veränderungen an | durch definiertes und strukturiertes Schema nicht flexibel |
Studyflix vernetzt: Hier ein Video aus einem anderen Bereich
Nach Beantwortung speichern wir deine Antwort, um Studyflix zu verbessern. Mehr dazu erfährst du in unserer Datenschutzerklärung.
Data Lakes: Chancen und Herausforderungen
Aufgrund seiner flexiblen Eigenschaften bieten Data Lakes viele Chancen für ein Unternehmen:
-
Schnelligkeit: Da die Daten in ihrem Ursprungsformat gespeichert werden können, sind die Speichervorgänge sehr schnell. Es ist keine vorherige Strukturierung oder Umformatierung nötig. So können beispielsweise Daten aus dem Internet in Echtzeit gespeichert werden.
-
mehr Auswertungsmöglichkeiten: Der Data Lake nimmt sämtliche Daten auf, ohne ihren Zweck bestimmt zu haben. Er sortiert also noch keine Daten aus. Somit schränkt er die Analysemöglichkeiten nicht schon bei der Datenspeicherung ein.
-
Flexibilität: Da keine Struktur vorgegeben ist, lassen sich Data Lakes schnell an Veränderungen anpassen.
- Kombination verschiedener Daten: Da ein Data Lake sehr unterschiedliche Daten zusammenbringen kann, sind aussagekräftigere und tiefer gehende Analysen möglich. Diese können zu einem Wettbewerbsvorteil führen.
Aber bei all den Chancen gibt es auch einige Herausforderungen:
-
hohe Nutzeranforderung: freie Analysen können meist nur von Experten durchgeführt werden, die die Struktur und Zusammenhänge der Daten kennen.
-
erhöhte Sicherheitsanforderung: Je mehr Daten gespeichert werden und je mehr Zusammenhänge sich zwischen den Daten herstellen lassen, desto besser müssen sie geschützt werden. Deshalb benötigt ein Data Lake durchdachte Sicherheits- und Datenschutzkonzepte. Im Zuge dessen sollten beispielsweise nicht alle Nutzer die gleichen Zugriffsrechte bekommen.
- Intakthaltung: Eine große Herausforderung der Data-Lake-Architektur besteht darin, dass Rohdaten ohne Übersicht über den Inhalt gespeichert werden. Um die Daten nutzbar zu machen, muss ein Data Lake deshalb über definierte Mechanismen zum Katalogisieren und Sichern von Daten verfügen. Sonst können Daten womöglich nicht gefunden werden. Der Datensee wird dann zu einem Datensumpf.
Ein Data Lake (deutsch: Datensee) ist in der Informatik ein Repository, das unstrukturierte Daten in ihrem Rohformat aufnimmt. Wenn keine regelmäßigen Datenqualitäts- und Data-Governance-Maßnahmen durchgeführt werden, wird er zu einem Datensumpf.
In einem Datensumpf sind die Daten aufgrund fehlender Metadaten, gebrochener Beziehungen und mangelhafter Organisation nicht mehr sinnvoll für Analysen nutzbar.
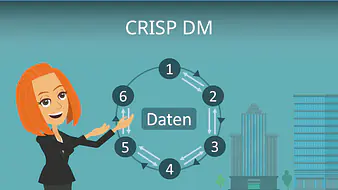
CRISP DM
Aber nicht nur die Speicherung von Daten ist wichtig, sondern viel mehr, was ein Unternehmen mit den Daten anfängt.
Die strukturierte Auswertung von Daten wird auch „Data Mining“ genannt. Dabei wird unter anderem auch das maschinelle Lernen eingesetzt, um neue Trends und Muster ausfindig zu machen. Diese Erkenntnisse aus den Daten helfen einem Unternehmen, bessere geschäftliche Entscheidungen zu treffen.
Der CRISP-DM (Cross-Industry Standard Process for Data Mining) ist ein einheitlicher Standard für die Entwicklung von Data Mining Prozessen. Er hilft Unternehmen bei der Strukturierung ihrer Data Mining Projekte. Der CRISP-DM besteht aus 6 Schritten:
- Aufgabendefinition
- Auswahl der relevanten Datenbestände
- Vorbereitung der Daten
- Auswahl und Anwendung von Data Mining Methoden
- Auswertung der Ergebnisse
- Anwendung der Ergebnisse
Möchtest du noch mehr über die einzelnen Schritte erfahren? Dann schau dir einfach unser Video zu dem Thema an!

Data Lake — häufigste Fragen
(ausklappen)
Data Lake — häufigste Fragen
(ausklappen)-
Was ist der Unterschied zwischen Datenbank und Data Warehouse?Man verwendet eine Datenbank vor allem zur operativen Speicherung und Verarbeitung aktueller, stark strukturierter Daten für Anwendungen und Transaktionen. Man verwendet ein Data Warehouse, um Daten aus mehreren Quellen zu sammeln, für Analysen aufzubereiten und in einem einheitlichen Schema für Reporting und Business-Intelligence-Abfragen bereitzuhalten.
-
Was ist der Unterschied zwischen Data Lake und Data Warehouse?Man speichert in einem Data Lake Daten aus vielen Quellen im Rohformat, während man in einem Data Warehouse vorab aufbereitete und strukturierte Daten ablegt. Beim Data Lake steht der Analysezweck beim Speichern noch nicht fest, deshalb strukturiert man Daten erst bei Bedarf. Ein Data Warehouse ist für sofortige Analysen durch Business-Anwender ausgelegt, ein Data Lake eher für Data Scientists.
-
Wann wird ein Data Lake zum Datensumpf?Ein Data Lake wird zum Datensumpf, wenn man Rohdaten ohne ausreichende Katalogisierung, Metadaten und regelmäßige Datenqualitäts- sowie Data-Governance-Maßnahmen ablegt. Dann gehen Struktur und Beziehungen zwischen Daten verloren, sodass man relevante Daten kaum noch findet und die Inhalte für Analysen nicht mehr zuverlässig nutzbar sind.
-
Wozu braucht man CRISP-DM beim Data Mining?CRISP-DM braucht man beim Data Mining, um ein Data-Mining-Projekt in einen klaren, wiederholbaren Ablauf zu bringen. Der Standard führt von der Aufgabendefinition über Datenauswahl und Datenvorbereitung zur Anwendung von Methoden, Auswertung der Ergebnisse und ihrer Umsetzung. Dadurch bleiben fachliches Ziel und Analyseschritte sauber verknüpft.
Datenmanagement verstehen
Ein Data Lake gehört zum Datenmanagement in Unternehmen und ist ein wichtiger Teil moderner IT-Systeme. Wer sich mit Datenmanagement beschäftigt, vergleicht verschiedene Speicherformen, ordnet Datenquellen ein und betrachtet den Weg von Rohdaten bis zur Analyse. So wird klar, warum Struktur, Zugriff und Pflege von Daten für gute Auswertungen wichtig sind. Im Informatikbereich findest du passende Videos zu diesem und verwandten Themen.