
Du weißt nicht was es mit der sogenannten Schichtenarchitektur in der Informatik auf sich hat? Wir zeigen es dir in zwei Beiträgen!
Inhaltsübersicht
Modell zur Entkopplung von Klassen
Die Schichtenarchitektur besteht im Groben aus drei Schichten, die je nach Genauigkeit noch weiter untergliedert werden können.
Uns reicht hier aber die Aufgliederung in drei Schichten. Diese sind die GUI-Schicht, die Fachkonzeptschicht und die Datenhaltungsschicht.

Die GUI-Schicht enthält die Benutzeroberfläche inklusive Dialogführung. Sie stellt damit die Daten der Fachkonzeptschicht dar. Diese bildet den funktionalen Kern des Programms, denn sie manipuliert die fachlichen Daten. Darunter liegt die Datenhaltungsschicht, die die Datenspeicherung realisiert. Das heißt, sie sorgt für den Zugriff auf gespeicherte Daten.
Durch die Anwendung dieses Modells werden Klassen weniger abhängig voneinander. Das wird auch Entkopplung genannt. Diese Entkopplung kannst du erreichen, indem du die verschiedenen Klassen aufteilst und Schichten durch einzelne Pakete modulierst und implementierst.
Konkretisierung der Fachkonzeptschicht
Folgt man der strengen Schichtenarchitektur, so können Objekte einer Schicht nur auf Objekte der direkt darunterliegenden Schicht zugreifen, nicht aber anders herum. Um das ganze etwas besser zu verstehen, erklären wir dir die einzelnen Schichten jetzt genauer.

Beginnen wir mit der Fachkonzeptschicht. Sie dient im Allgemeinen der Verwaltung der fachlichen Daten. Dies erfolgt meist mittels Containerklassen. Containerklassen bestehen aus Objekten der zugehörigen Datenklasse, die über eine Komposition an den Container angebunden werden.
Das erstellte Containerobjekt besitzt wichtige Standardverwaltungsoperationen zum Hinzufügen und Löschen von Datenobjekten. Wir können aber auch mittels des sogenannten Iterator-Musters die Gesamtheit der in ihm enthaltenen Datenobjekte durchlaufen.

Wenn wir Objekte aus Datenklassen einer Containerklasse hinzufügen, werden deren Klassenattribute und -operationen zu den Objektattributen und -operationen der Containerklasse.
Dies ist allerdings für den konkreten Programmablauf nicht so wichtig, denn es wird nur ein Objekt der Containerklasse erzeugt. Das lässt sich mittels des sogenannten Singleton-Musters realisieren.
Studyflix vernetzt: Hier ein Video aus einem anderen Bereich
Singleton-Muster und Iterator-Muster
Das Singleton-Muster ist nichts weiter als ein Muster, das uns erlaubt, die Anzahl unserer erzeugten Objekte zu kontrollieren. Konkret müssen wir dafür unseren Konstruktor private deklarieren. Das klingt zwar erstmal sinnlos, aber nachher wird dir noch ein Licht aufgehen, warum.
Unsere Objekte verwalten wir nun durch ein Klassenattribut namens unique, auf das wir Zugriff über eine öffentliche Klassenoperation gewähren. Diese nennen wir instance().
Diese Funktion überprüft, wenn sie aufgerufen wird, ob bereits ein Objekt des Klassentyps vorhanden ist und ruft, wenn dies nicht der Fall ist, unseren Konstruktor auf. Dies ist nun möglich, da wir uns innerhalb derselben Klasse befinden.

Das andere Muster, das wir brauchen, ist das bereits erwähnte Iterator-Muster. Es erlaubt uns Objekte einer intern verwalteten Liste von außen zu durchlaufen. Das hat den Vorteil, dass der Zugriff einheitlich erfolgt und unabhängig von der internen Implementierung bleibt.
Damit das funktioniert muss unsere Liste durch eine beliebige API-Collection-Klasse implementiert sein. Dann bauen wir in unserer Klasse die Schnittstelle java.lang.Iterable ein.
Nun können wir uns mittels der Methode iterator() den Iterator für die interne Liste zurückgeben lassen. Diese Methode ist bereits für alle Collection-Klassen implementiert.

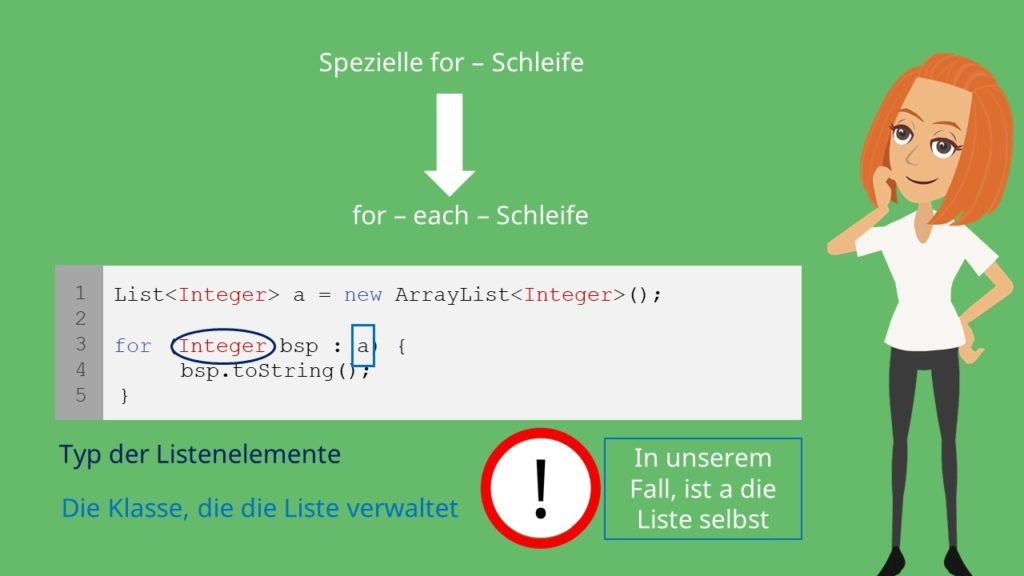
Aber wie durchlaufen wir jetzt alle Einträge? Dafür gibt es eine spezielle for-Schleife – und zwar die sogenannte for-each-Schleife.
Dabei steht Integer für den Typ der Listenelemente und a für die Klasse, die die Liste verwaltet oder in unserem Fall die Liste selbst.
Jetzt weißt du alles Wichtige zur Fachkonzeptschicht. Im nächsten Beitrag erklären wir dir noch die GUI- und die Datenhaltungsschicht.
Schichtenarchitektur I — häufigste Fragen
(ausklappen)
Schichtenarchitektur I — häufigste Fragen
(ausklappen)-
Welche Nachteile hat die Schichtenarchitektur?Nachteile der Schichtenarchitektur sind zusätzlicher Struktur- und Abstimmungsaufwand zwischen den Schichten und oft mehr „Durchreichen“ von Daten und Aufrufen über mehrere Ebenen. Strenge Regeln können außerdem unflexibel wirken, wenn eine Funktion eigentlich Informationen aus einer weiter unten liegenden Schicht direkt bräuchte.
-
Warum dürfen Klassen in der Schichtenarchitektur nur auf die direkt darunterliegende Schicht zugreifen?Klassen dürfen nur auf die direkt darunterliegende Schicht zugreifen, weil dadurch die Abhängigkeiten klein und übersichtlich bleiben. Änderungen in einer Schicht betreffen dann weniger andere Teile des Programms, und die Zuständigkeiten der Schichten (GUI, Fachkonzept, Datenhaltung) bleiben klar getrennt.
-
Warum wird die Containerklasse in der Fachkonzeptschicht oft als Singleton umgesetzt?Die Containerklasse wird in der Fachkonzeptschicht oft als Singleton umgesetzt, damit es genau eine zentrale Stelle gibt, die die fachlichen Datenobjekte verwaltet. So greifen alle Teile der Fachlogik auf denselben Bestand zu, und Hinzufügen oder Löschen wird konsistent über ein einziges Containerobjekt gesteuert.
-
Wie macht man eine Containerklasse in Java so, dass man sie mit einer for-each-Schleife durchlaufen kann?Eine Containerklasse macht man für eine for-each-Schleife nutzbar, indem sie
Iterableimplementiert und eine Methodeiterator()bereitstellt.iterator()gibt dabei den Iterator der intern verwendeten Collection zurück, zum Beispielreturn liste.iterator();, sodass die for-each-Schleife die Elemente nacheinander abrufen kann.
Nach Beantwortung speichern wir deine Antwort, um Studyflix zu verbessern. Mehr dazu erfährst du in unserer Datenschutzerklärung.
Softwarearchitektur verstehen
Die Schichtenarchitektur ist ein bekanntes Modell aus der Softwarearchitektur. Du strukturierst Programme in klare Teile wie Oberfläche, Logik und Datenzugriff und legst feste Schnittstellen zwischen ihnen fest. So erkennst du, welche Klassen zusammengehören, welche Abhängigkeiten erlaubt sind und wo du Änderungen machen kannst, ohne den Rest zu brechen. Weitere Videos dazu findest du in unserem Informatikbereich.